Debugging like a scientist
Today we had a small internal incident at work, which reminded me of an excellent strategy for debugging strange and hard to understand issues: the scientific method!
Finding truth the quick way
At the heart of the scientific method is a simple loop, that runs from making observations, to forming hypotheses, to testing those hypotheses. Testing them leads to more observations, and fresh hypotheses along they way. In this way you can rapidly iterate through possibilities, trying to refute the most plausible hypotheses each time, until you find solid evidence that one of your hypotheses is correct.
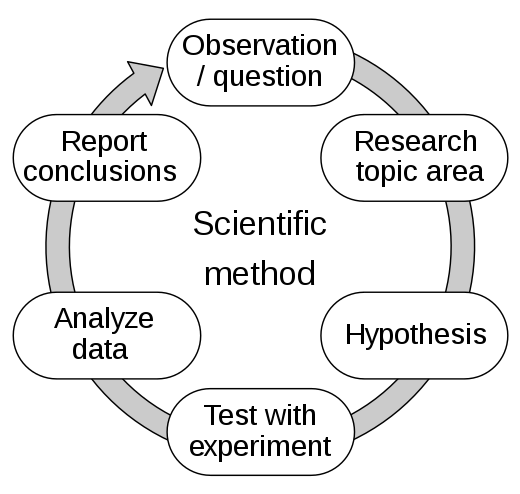
This style of thinking is pretty automatic for small things, but the more complex the issue, the harder it is to systematically make progress on it. That’s when it’s useful to add some structure to your thinking, and get it all out in a document. This frees your mind from having to remember details, and gives you a process for continuously making progress in tricky situations.
Debugging this way in practice
In operations, many issues are transient or quickly fixed with no changes — I usually try to see if the issue will resolve itself or can be resolved by restarting the service, something that’s fine at small scale. But if these things fail, I escalate to proper debugging.
I start a new document, either in Notion, Google Docs or Vimwiki if I’m solo. It has three sections:
- Problem: where I write what’s wrong
- Evidence: where I collect stack traces, snippets of log data, and all the things I observe along the way, usually as dot points
- Hypotheses: where I collect initial ideas about why the problem could be occurring
For example, in today’s issue:
Problem
Our internal deploy queue has been failing with an error since 15:30 CET
Evidence
- Stacktrace reported in Slack with 502 Gateway error in site baking code
Hypotheses
- ? We deployed a bad change
- ? A third-party service is having an outage
- ? An internal service is having an outage
Note that each hypothesis has a ? in front of it, which signifies that I’m unclear if it’s true or not. If I gain enough evidence one way or another, I promote the ? to a ✓ or a ✗. I also try to order my hypotheses from most likely to least likely, in my judgement.
Structuring hypotheses
Each hypothesis that I’m examining also gets substructure. There are three sections:
- …since: points of evidence or argument in favour
- …but: points of evidence or argument against
- …predicts: evidence that I don’t have yet, but that would confirm or deny this hypothesis
For example:
Hypotheses
- ? We deployed bad code
- …since
- Our systems don’t usually fail without a change
- …predicts
- ? We deployed code changes just before 15:30 CET
Then I can go check this specific prediction and come to a conclusion quickly. In this case, it’s a ✗ to both the prediction and the hypothesis: no changes had been deployed for more than 12h beforehand. On to the next hypothesis!
Sometimes there’s no good evidence for any of your hypotheses, they all seem false. In that case, you have to be a little analytical and creative to imagine what might have happened, or you might just need to explore the system or code more to help you form good hypotheses.
Good for coding, good for ops
When something people are using has issues, there are other factors to consider: communicating effectively to current users, recording the timeline of events, etc. But this overall approach has helped me sort through the most difficult issues, in the same way that it helps researchers to tackle much larger problems. Give it a try next time you get stuck!